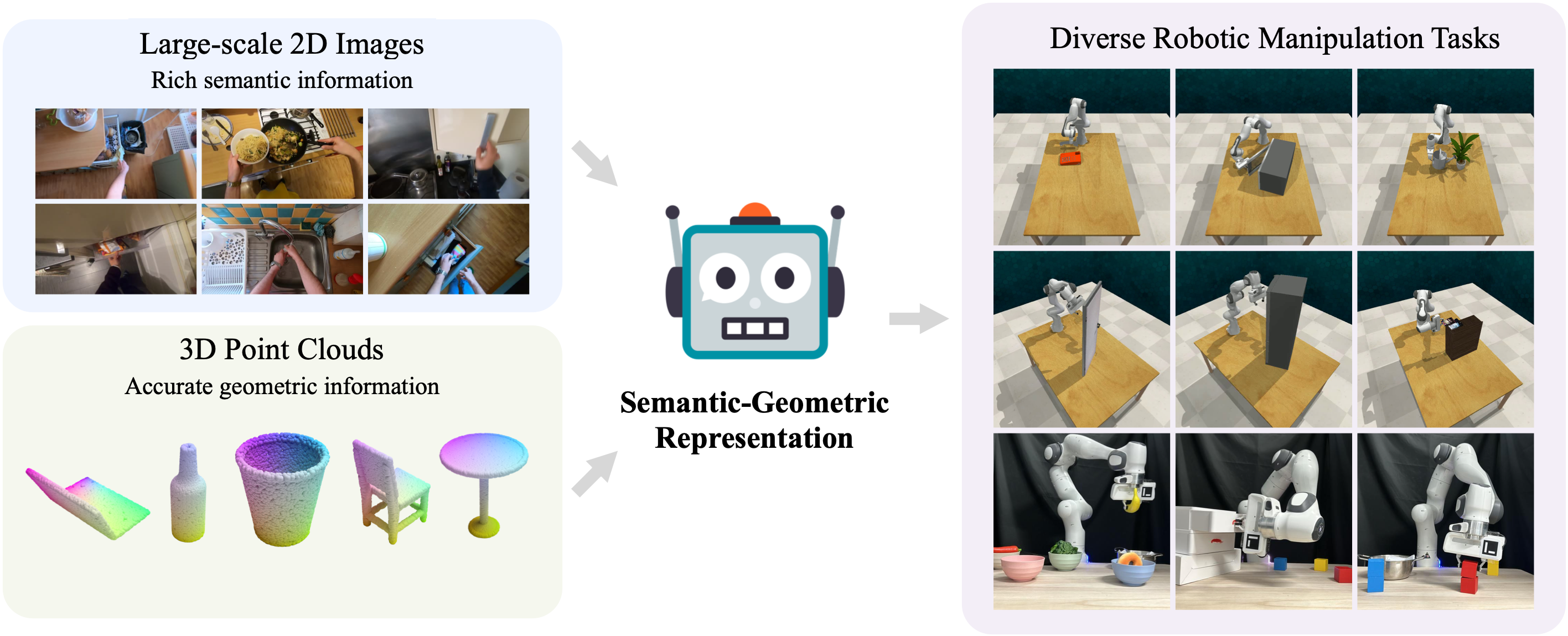
Robots rely heavily on sensors, especially RGB and depth cameras, to perceive and interact with the world. RGB cameras record 2D images with rich semantic information while missing part of precise spatial information. On the other side, depth cameras offer critical 3D geometry data but limited semantics. Therefore, integrating both modalities is crucial for learning visual representations for robotic perception and control. However, current research predominantly focuses on only one of these modalities, neglecting the benefits of incorporating both.
To this end, we present Semantic-Geometric Representation (SGR), a universal perception module for robotics that leverages the rich semantic information of large-scale pre-trained 2D models and inherits the merits of 3D spatial reasoning.
Our experiments demonstrate that SGR empowers the agent to successfully complete a diverse range of simulated and real-world robotic manipulation tasks, outperforming state-of-the-art methods significantly in both single-task and multi-task settings. Furthermore, SGR possesses the capability to generalize to novel semantic attributes, setting it apart from the other methods.
We first utilize a large vision foundation model, pre-trained on massive amounts of internet data (e.g., CLIP), to encode semantic feature maps from 2D images. Secondly, the context-rich 2D feature vectors are back-projected into 3D space and combined with the point cloud features that are extracted from point clouds using a shallow point-based network. These fused features are fed into a number of set abstraction (SA) blocks, which jointly model the cross-modal interaction between 2D semantics and 3D geometry information. Finally, based on the output representations from the SA blocks, we predict the robotic action to execute.
@article{zhang2023universal,
title={A Universal Semantic-Geometric Representation for Robotic Manipulation},
author={Zhang, Tong and Hu, Yingdong and Cui, Hanchen and Zhao, Hang and Gao, Yang},
journal={arXiv preprint arXiv:2306.10474},
year={2023}
}